Justification of the abstraction
Clearly, it doesn’t make sense to talk of the global state of a computer system, or of coordination between computers at the level of individual instructions. The electrical signals in a computer travel at the speed of light, about \( 2·10^8 \frac{m}{sec}\), and the clock cycles of modern CPUs are at least one gigahertz, so information cannot travel more than \( 2x10^8· 10^{-9} = 0.2 m\) during a clock cycle of a CPU. There is simply not enough time to coordinate individual instructions of more than one CPU.
Nevertheless, that is precisely the abstraction that we will use! We will assume
that we have a bird’s-eye view of the global state of the system, and that a state-
ment of one process executes by itself and to completion, before the execution of a
statement of another process commences.
It is a convenient fiction to regard the execution of a concurrent program as being carried out by a global entity who at each step selects the process from which the next statement will be executed. The term interleaving comes from this image: just as you might interleave the cards from several decks of playing cards by selecting cards one by one from the decks, so we regard this entity as interleaving statements by selecting them one by one from the processes. The interleaving is arbitrary, that is—with one exception to be discussed in Section 2.7—we do not restrict the choice of the process from which the next statement is taken.
The abstraction defined is highly artificial, so we will spend some time justifying it for various possible computer architectures.
Multitasking systems
Consider the case of a concurrent program that is being executed by multitasking, that is, by sharing the resources of one computer. Obviously, with a single CPU there is no question of the simultaneous execution of several instructions. The se- lection of the next instruction to execute is carried out by the CPU and the operating system. Normally, the next instruction is taken from the same process from which the current instruction was executed; occasionally, interrupts from I/O devices or internal timers will cause the execution to be interrupted. A new process called an interrupt handler will be executed, and upon its completion, an operating system function called the scheduler may be invoked to select a new process to execute.
This mechanism is called a context switch. The diagram below shows the memory divided into five segments, one for the operating system code and data, and four for the code and data of the programs that are running concurrently:
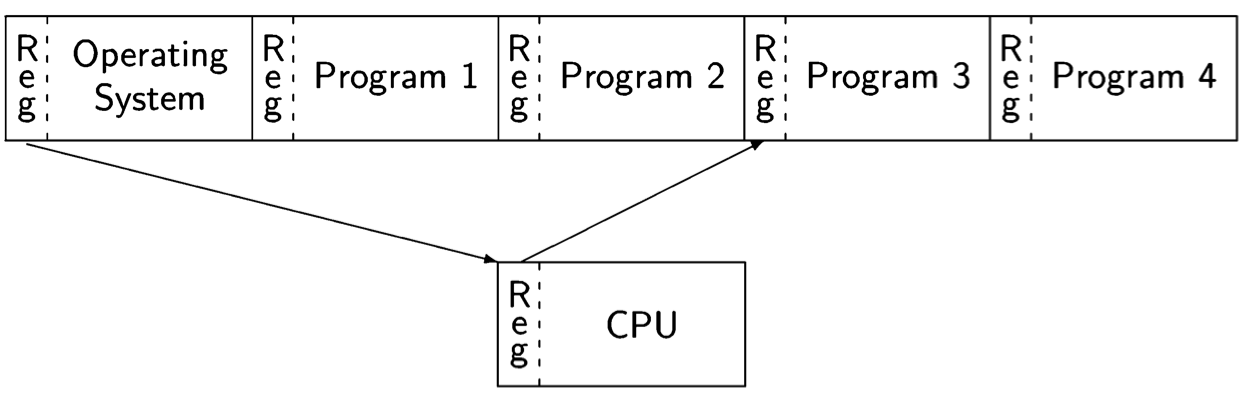
When the execution is interrupted, the registers in the CPU (not only the registers used for computation, but also the control pointer and other registers that point to the memory segment used by the program) are saved into a prespecified area in the program’s memory. Then the register contents required to execute the interrupt handler are loaded into the CPU. At the conclusion of the interrupt processing, the symmetric context switch is performed, storing the interrupt handler registers and loading the registers for the program. The end of interrupt processing is a convenient time to invoke the operating system scheduler, which may decide to perform the context switch with another program, not the one that was interrupted.
In a multitasking system, the non-intuitive aspect of the abstraction is not the in- terleaving of atomic statements (that actually occurs), but the requirement that any arbitrary interleaving is acceptable. After all, the operating system scheduler may only be called every few milliseconds, so many thousands of instructions will be executed from each process before any instructions are interleaved from another. We defer a discussion of this important point to Section 2.4.
Multiprocessor computers
A multiprocessor computer is a computer with more than one CPU. The memory is physically divided into banks of local memory, each of which can be accessed only by one CPU, and global memory, which can be accessed by all CPUs:
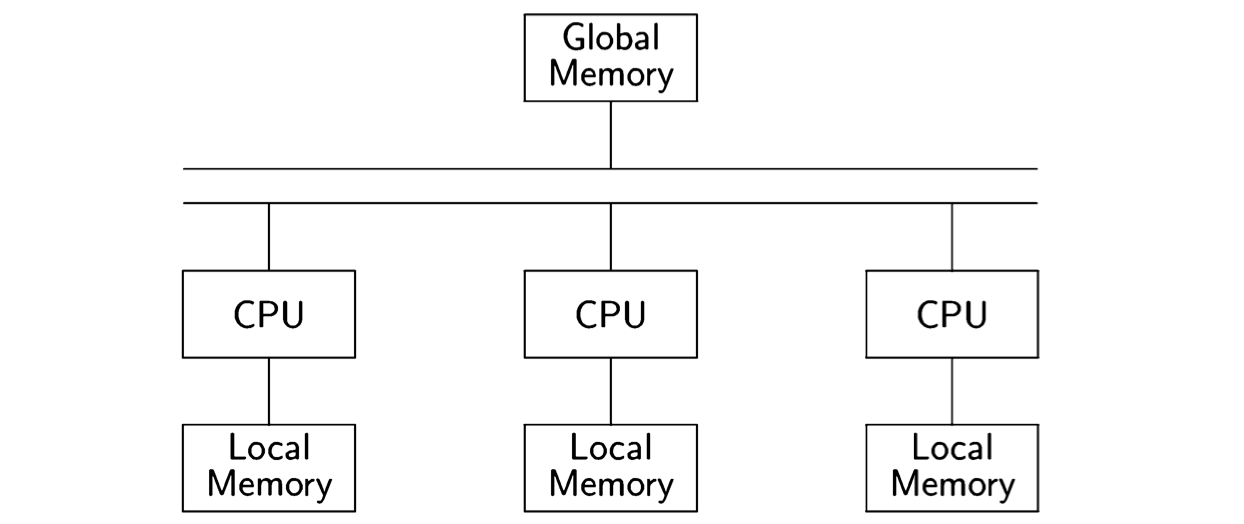
If we have a sufficient number of CPUs, we can assign each process to its own CPU. The interleaving assumption no longer corresponds to reality, since each CPU is executing its instructions independently. Nevertheless, the abstraction is useful here.
As long as there is no contention, that is, as long as two CPUs do not attempt to access the same resource (in this case, the global memory), the computations defined by interleaving will be indistinguishable from those of truly parallel exe- cution. With contention, however, there is a potential problem. The memory of a computer is divided into a large number of cells that store data which is read and written by the CPU. Eight-bit cells are called bytes and larger cells are called words, but the size of a cell is not important for our purposes. We want to ask what might happen if two processors try to read or write a cell simultaneously so that the operations overlap. The following diagram indicates the problem:
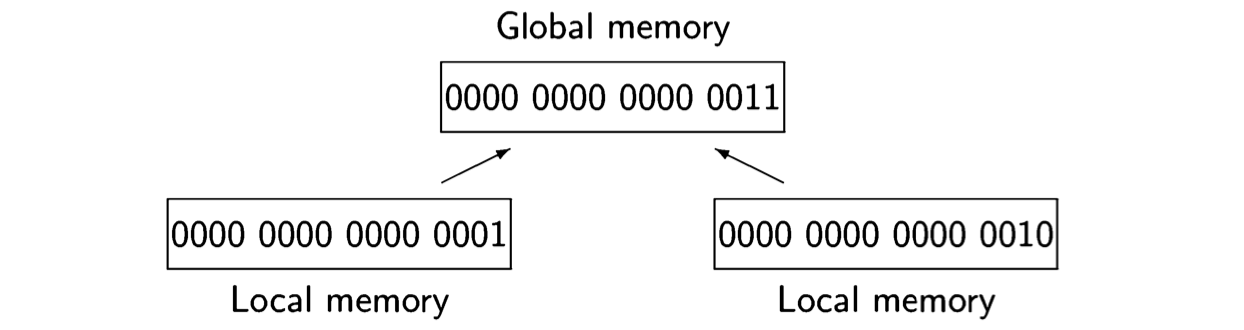
It shows 16-bit cells of local memory associated with two processors; one cell contains the value 0 ... 01 and one contains 0 ... 10 = 2. If both processors write to the cell of global memory at the same time, the value might be undefined; for example, it might be the value 0 ... 11 = 3 obtained by or’ing together the bit representations of 1 and 2.
In practice, this problem does not occur because memory hardware is designed so that (for some size memory cell) one access completes before the other com- mences. Therefore, we can assume that if two CPUs attempt to read or write the same cell in global memory, the result is the same as if the two instructions were executed in either order. In effect, atomicity and interleaving are performed by the hardware.
Other less restrictive abstractions have been studied; we will give one example of an algorithm that works under the assumption that if a read of a memory cell over- laps a write of the same cell, the read may return an arbitrary value (Section 5.3).
The requirement to allow arbitrary interleaving makes a lot of sense in the case of a multiprocessor; because there is no central scheduler, any computation resulting from interleaving may certainly occur.
Distributed systems
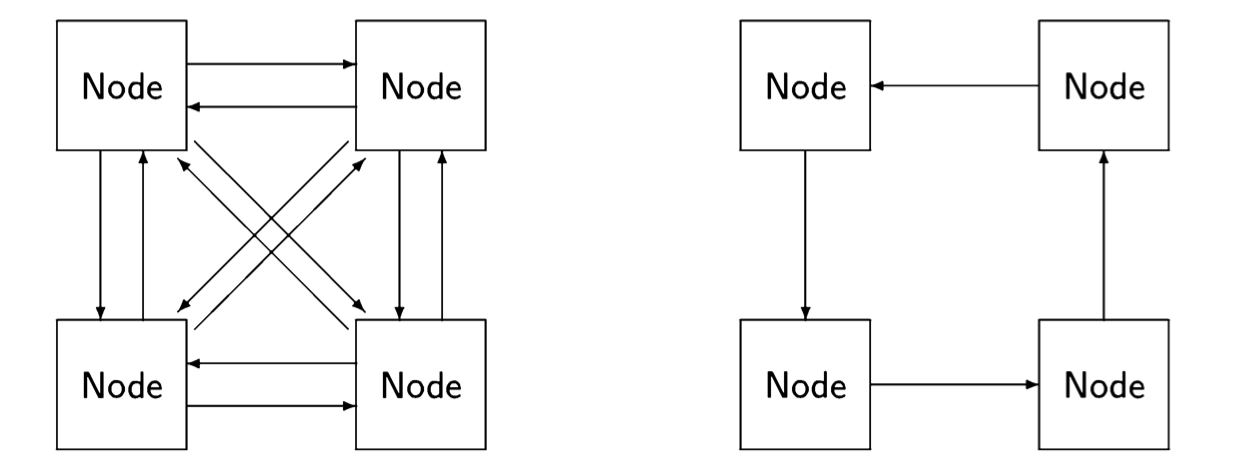
A distributed system is composed of several computers that have no global resources; instead, they are connected by communications channels enabling them to send messages to each other. The language of graph theory is used in discussing distributed systems; each computer is a node and the nodes are connected by (di-rected) edges. The following diagram shows two possible schemes for interconnecting nodes: on the left, the nodes are fully connected while on the right they are connected in a ring:
In a distributed system, the abstraction of interleaving is, of course, totally false, since it is impossible to coordinate each node in a geographically distributed sys- tem. Nevertheless, interleaving is a very useful fiction, because as far as each node is concerned, it only sees discrete events: it is either executing one of its own statements, sending a message or receiving a message. Any interleaving of all the events of all the nodes can be used for reasoning about the system, as long as the interleaving is consistent with the statement sequences of each individual node and with the requirement that a message be sent before it is received.
Distributed systems are considered to be distinct from concurrent systems. In a concurrent system implemented by multitasking or multiprocessing, the global memory is accessible to all processes and each one can access the memory efficiently. In a distributed system, the nodes may be geographically distant from each other, so we cannot assume that each node can send a message directly to all other nodes. In other words, we have to consider the topology or connectedness of the system, and the quality of an algorithm (its simplicity or efficiency) may be dependent on a specific topology. A fully connected topology is extremely efficient in that any node can send a message directly to any other node, but it is extremely expensive, because for n nodes, we need \( n · (n-1) \approx n^2 \) communications channels. The ring topology has minimal cost in that any node has only one communications line associated with it, but it is inefficient, because to send a message from one arbitrary node to another we may need to have it relayed through up to \( n - 2 \) other nodes.
A further difference between concurrent and distributed systems is that the behavior of systems in the presence of faults is usually studied within distributed systems. In a multitasking system, hardware failure is usually catastrophic since it affects all processes, while a software failure may be relatively innocuous (if the process simply stops working), though it can be catastrophic (if it gets stuck in an infinite loop at high priority). In a distributed system, while failures can be catastrophic for single nodes, it is usually possible to diagnose and work around a faulty node, because messages may be relayed through alternate communication paths. In fact, the success of the Internet can be attributed to the robustness of its protocols when individual nodes or communications channels fail.